Java Read File and Separate Name and Age

Reading files in Coffee is the cause for a lot of defoliation. There are multiple ways of accomplishing the same chore and information technology's ofttimes non articulate which file reading method is best to use. Something that'due south quick and dirty for a small case file might non be the best method to use when y'all need to read a very large file. Something that worked in an earlier Coffee version, might not be the preferred method anymore.
This article aims to exist the definitive guide for reading files in Java seven, 8 and 9. I'thousand going to cover all the means you tin read files in Java. Too often, y'all'll read an commodity that tells you ane mode to read a file, only to discover afterward at that place are other ways to practice that. I'grand actually going to encompass fifteen different means to read a file in Java. I'1000 going to cover reading files in multiple ways with the core Coffee libraries as well as two third party libraries.
But that's not all – what good is knowing how to do something in multiple ways if you don't know which way is all-time for your state of affairs?
I besides put each of these methods to a real operation examination and document the results. That manner, you lot volition have some hard data to know the performance metrics of each method.
Methodology
JDK Versions
Java code samples don't alive in isolation, peculiarly when it comes to Java I/O, equally the API keeps evolving. All code for this commodity has been tested on:
- Java SE vii (jdk1.7.0_80)
- Java SE eight (jdk1.8.0_162)
- Coffee SE ix (jdk-9.0.4)
When in that location is an incompatibility, information technology will be stated in that department. Otherwise, the code works unaltered for different Java versions. The main incompatibility is the use of lambda expressions which was introduced in Java 8.
Java File Reading Libraries
In that location are multiple ways of reading from files in Java. This article aims to be a comprehensive collection of all the different methods. I will cover:
- java.io.FileReader.read()
- java.io.BufferedReader.readLine()
- java.io.FileInputStream.read()
- java.io.BufferedInputStream.read()
- java.nio.file.Files.readAllBytes()
- java.nio.file.Files.readAllLines()
- java.nio.file.Files.lines()
- java.util.Scanner.nextLine()
- org.apache.commons.io.FileUtils.readLines() – Apache Eatables
- com.google.common.io.Files.readLines() – Google Guava
Closing File Resource
Prior to JDK7, when opening a file in Coffee, all file resources would need to be manually closed using a try-catch-finally block. JDK7 introduced the effort-with-resources argument, which simplifies the process of closing streams. You no longer need to write explicit lawmaking to close streams because the JVM will automatically close the stream for you, whether an exception occurred or not. All examples used in this commodity employ the try-with-resources argument for importing, loading, parsing and closing files.
File Location
All examples will read test files from C:\temp.
Encoding
Character encoding is non explicitly saved with text files so Java makes assumptions about the encoding when reading files. Commonly, the assumption is right but sometimes you want to be explicit when instructing your programs to read from files. When encoding isn't correct, you lot'll see funny characters appear when reading files.
All examples for reading text files use two encoding variations:
Default system encoding where no encoding is specified and explicitly setting the encoding to UTF-8.
Download Code
All lawmaking files are available from Github.
Lawmaking Quality and Code Encapsulation
There is a difference between writing code for your personal or work project and writing code to explicate and teach concepts.
If I was writing this code for my own projection, I would use proper object-oriented principles similar encapsulation, abstraction, polymorphism, etc. Just I wanted to make each example stand lonely and easily understood, which meant that some of the lawmaking has been copied from one case to the adjacent. I did this on purpose because I didn't desire the reader to accept to figure out all the encapsulation and object structures I then cleverly created. That would take away from the examples.
For the same reason, I chose NOT to write these example with a unit testing framework like JUnit or TestNG considering that'southward non the purpose of this commodity. That would add together another library for the reader to understand that has nothing to practise with reading files in Coffee. That's why all the example are written inline inside the master method, without extra methods or classes.
My principal purpose is to brand the examples as easy to understand as possible and I believe that having actress unit testing and encapsulation code will not help with this. That doesn't hateful that's how I would encourage yous to write your ain personal code. It'due south but the way I chose to write the examples in this commodity to make them easier to empathize.
Exception Handling
All examples declare whatsoever checked exceptions in the throwing method declaration.
The purpose of this article is to show all the dissimilar means to read from files in Coffee – it's not meant to evidence how to handle exceptions, which will be very specific to your situation.
Then instead of creating unhelpful effort catch blocks that but print exception stack traces and clutter upward the code, all instance will declare any checked exception in the calling method. This will make the code cleaner and easier to empathize without sacrificing whatsoever functionality.
Future Updates
Every bit Java file reading evolves, I will be updating this commodity with any required changes.
File Reading Methods
I organized the file reading methods into three groups:
- Archetype I/O classes that have been part of Coffee since before JDK 1.7. This includes the java.io and java.util packages.
- New Java I/O classes that take been part of Java since JDK1.7. This covers the java.nio.file.Files class.
- Third party I/O classes from the Apache Commons and Google Guava projects.
Classic I/O – Reading Text
1a) FileReader – Default Encoding
FileReader reads in one character at a time, without any buffering. Information technology's meant for reading text files. It uses the default character encoding on your arrangement, so I have provided examples for both the default example, also as specifying the encoding explicitly.
1
two
3
4
5
6
7
8
9
ten
11
12
13
14
15
sixteen
17
eighteen
xix
import java.io.FileReader ;
import coffee.io.IOException ;public class ReadFile_FileReader_Read {
public static void master( String [ ] pArgs) throws IOException {
Cord fileName = "c:\\temp\\sample-10KB.txt" ;endeavour ( FileReader fileReader = new FileReader (fileName) ) {
int singleCharInt;
char singleChar;
while ( (singleCharInt = fileReader.read ( ) ) != - 1 ) {
singleChar = ( char ) singleCharInt;//display 1 character at a fourth dimension
Arrangement.out.impress (singleChar) ;
}
}
}
}
1b) FileReader – Explicit Encoding (InputStreamReader)
Information technology'southward actually non possible to set the encoding explicitly on a FileReader so you have to use the parent class, InputStreamReader and wrap it around a FileInputStream:
1
ii
3
iv
v
6
7
viii
9
10
11
12
13
xiv
xv
sixteen
17
18
19
20
21
22
import java.io.FileInputStream ;
import java.io.IOException ;
import java.io.InputStreamReader ;public class ReadFile_FileReader_Read_Encoding {
public static void primary( String [ ] pArgs) throws IOException {
String fileName = "c:\\temp\\sample-10KB.txt" ;
FileInputStream fileInputStream = new FileInputStream (fileName) ;//specify UTF-8 encoding explicitly
attempt ( InputStreamReader inputStreamReader =
new InputStreamReader (fileInputStream, "UTF-viii" ) ) {int singleCharInt;
char singleChar;
while ( (singleCharInt = inputStreamReader.read ( ) ) != - one ) {
singleChar = ( char ) singleCharInt;
Arrangement.out.print (singleChar) ; //brandish one character at a time
}
}
}
}
2a) BufferedReader – Default Encoding
BufferedReader reads an entire line at a time, instead of one character at a time like FileReader. It's meant for reading text files.
ane
2
3
4
5
6
7
viii
9
10
11
12
13
14
15
16
17
import java.io.BufferedReader ;
import java.io.FileReader ;
import java.io.IOException ;public class ReadFile_BufferedReader_ReadLine {
public static void principal( String [ ] args) throws IOException {
String fileName = "c:\\temp\\sample-10KB.txt" ;
FileReader fileReader = new FileReader (fileName) ;try ( BufferedReader bufferedReader = new BufferedReader (fileReader) ) {
String line;
while ( (line = bufferedReader.readLine ( ) ) != goose egg ) {
System.out.println (line) ;
}
}
}
}
2b) BufferedReader – Explicit Encoding
In a similar mode to how nosotros set encoding explicitly for FileReader, we demand to create FileInputStream, wrap it inside InputStreamReader with an explicit encoding and pass that to BufferedReader:
one
2
three
4
5
half dozen
7
8
9
10
11
12
thirteen
14
fifteen
sixteen
17
18
xix
20
21
22
import java.io.BufferedReader ;
import java.io.FileInputStream ;
import java.io.IOException ;
import coffee.io.InputStreamReader ;public grade ReadFile_BufferedReader_ReadLine_Encoding {
public static void principal( String [ ] args) throws IOException {
String fileName = "c:\\temp\\sample-10KB.txt" ;FileInputStream fileInputStream = new FileInputStream (fileName) ;
//specify UTF-eight encoding explicitly
InputStreamReader inputStreamReader = new InputStreamReader (fileInputStream, "UTF-8" ) ;try ( BufferedReader bufferedReader = new BufferedReader (inputStreamReader) ) {
Cord line;
while ( (line = bufferedReader.readLine ( ) ) != nil ) {
System.out.println (line) ;
}
}
}
}
Classic I/O – Reading Bytes
1) FileInputStream
FileInputStream reads in 1 byte at a time, without whatsoever buffering. While it'due south meant for reading binary files such as images or audio files, it tin can still be used to read text file. It'southward similar to reading with FileReader in that y'all're reading ane character at a fourth dimension every bit an integer and you demand to cast that int to a char to run across the ASCII value.
By default, it uses the default character encoding on your arrangement, so I have provided examples for both the default case, as well as specifying the encoding explicitly.
1
2
3
four
five
6
7
eight
ix
10
11
12
xiii
xiv
fifteen
16
17
eighteen
19
20
21
import coffee.io.File ;
import java.io.FileInputStream ;
import java.io.FileNotFoundException ;
import java.io.IOException ;public form ReadFile_FileInputStream_Read {
public static void main( Cord [ ] pArgs) throws FileNotFoundException, IOException {
String fileName = "c:\\temp\\sample-10KB.txt" ;
File file = new File (fileName) ;try ( FileInputStream fileInputStream = new FileInputStream (file) ) {
int singleCharInt;
char singleChar;while ( (singleCharInt = fileInputStream.read ( ) ) != - 1 ) {
singleChar = ( char ) singleCharInt;
Organization.out.print (singleChar) ;
}
}
}
}
ii) BufferedInputStream
BufferedInputStream reads a set of bytes all at once into an internal byte array buffer. The buffer size tin be gear up explicitly or use the default, which is what we'll demonstrate in our example. The default buffer size appears to be 8KB simply I have non explicitly verified this. All performance tests used the default buffer size so it will automatically re-size the buffer when information technology needs to.
1
2
3
4
v
six
seven
8
9
10
11
12
13
14
xv
xvi
17
18
19
20
21
22
import java.io.BufferedInputStream ;
import java.io.File ;
import java.io.FileInputStream ;
import coffee.io.FileNotFoundException ;
import java.io.IOException ;public form ReadFile_BufferedInputStream_Read {
public static void primary( String [ ] pArgs) throws FileNotFoundException, IOException {
String fileName = "c:\\temp\\sample-10KB.txt" ;
File file = new File (fileName) ;
FileInputStream fileInputStream = new FileInputStream (file) ;try ( BufferedInputStream bufferedInputStream = new BufferedInputStream (fileInputStream) ) {
int singleCharInt;
char singleChar;
while ( (singleCharInt = bufferedInputStream.read ( ) ) != - one ) {
singleChar = ( char ) singleCharInt;
System.out.impress (singleChar) ;
}
}
}
}
New I/O – Reading Text
1a) Files.readAllLines() – Default Encoding
The Files grade is part of the new Java I/O classes introduced in jdk1.7. It only has static utility methods for working with files and directories.
The readAllLines() method that uses the default graphic symbol encoding was introduced in jdk1.eight and then this example will not work in Java 7.
i
2
3
4
5
half-dozen
seven
eight
9
10
eleven
12
13
14
15
xvi
17
import java.io.File ;
import coffee.io.IOException ;
import coffee.nio.file.Files ;
import java.util.List ;public class ReadFile_Files_ReadAllLines {
public static void master( String [ ] pArgs) throws IOException {
Cord fileName = "c:\\temp\\sample-10KB.txt" ;
File file = new File (fileName) ;List fileLinesList = Files.readAllLines (file.toPath ( ) ) ;
for ( Cord line : fileLinesList) {
Arrangement.out.println (line) ;
}
}
}
1b) Files.readAllLines() – Explicit Encoding
1
2
3
4
5
6
7
8
nine
ten
xi
12
13
14
fifteen
16
17
xviii
19
import java.io.File ;
import java.io.IOException ;
import java.nio.charset.StandardCharsets ;
import coffee.nio.file.Files ;
import coffee.util.List ;public grade ReadFile_Files_ReadAllLines_Encoding {
public static void main( String [ ] pArgs) throws IOException {
String fileName = "c:\\temp\\sample-10KB.txt" ;
File file = new File (fileName) ;//employ UTF-eight encoding
List fileLinesList = Files.readAllLines (file.toPath ( ), StandardCharsets.UTF_8 ) ;for ( String line : fileLinesList) {
System.out.println (line) ;
}
}
}
2a) Files.lines() – Default Encoding
This lawmaking was tested to piece of work in Java 8 and 9. Coffee 7 didn't run because of the lack of back up for lambda expressions.
1
2
three
4
five
6
7
8
9
10
11
12
13
fourteen
15
16
17
import coffee.io.File ;
import java.io.IOException ;
import java.nio.file.Files ;
import coffee.util.stream.Stream ;public class ReadFile_Files_Lines {
public static void chief( String [ ] pArgs) throws IOException {
Cord fileName = "c:\\temp\\sample-10KB.txt" ;
File file = new File (fileName) ;effort (Stream linesStream = Files.lines (file.toPath ( ) ) ) {
linesStream.forEach (line -> {
System.out.println (line) ;
} ) ;
}
}
}
2b) Files.lines() – Explicit Encoding
Only like in the previous instance, this code was tested and works in Java 8 and ix but not in Java 7.
1
2
3
4
5
6
7
8
9
10
xi
12
13
fourteen
15
sixteen
17
18
import java.io.File ;
import java.io.IOException ;
import java.nio.charset.StandardCharsets ;
import java.nio.file.Files ;
import java.util.stream.Stream ;public class ReadFile_Files_Lines_Encoding {
public static void chief( String [ ] pArgs) throws IOException {
String fileName = "c:\\temp\\sample-10KB.txt" ;
File file = new File (fileName) ;endeavour (Stream linesStream = Files.lines (file.toPath ( ), StandardCharsets.UTF_8 ) ) {
linesStream.forEach (line -> {
System.out.println (line) ;
} ) ;
}
}
}
3a) Scanner – Default Encoding
The Scanner course was introduced in jdk1.7 and can be used to read from files or from the console (user input).
1
2
three
four
v
vi
7
8
9
x
11
12
13
14
xv
16
17
18
19
import java.io.File ;
import java.io.FileNotFoundException ;
import java.util.Scanner ;public form ReadFile_Scanner_NextLine {
public static void chief( String [ ] pArgs) throws FileNotFoundException {
String fileName = "c:\\temp\\sample-10KB.txt" ;
File file = new File (fileName) ;try (Scanner scanner = new Scanner(file) ) {
String line;
boolean hasNextLine = false ;
while (hasNextLine = scanner.hasNextLine ( ) ) {
line = scanner.nextLine ( ) ;
Organisation.out.println (line) ;
}
}
}
}
3b) Scanner – Explicit Encoding
1
ii
three
four
5
6
7
8
ix
ten
xi
12
13
fourteen
fifteen
16
17
xviii
19
20
import java.io.File ;
import coffee.io.FileNotFoundException ;
import java.util.Scanner ;public class ReadFile_Scanner_NextLine_Encoding {
public static void principal( String [ ] pArgs) throws FileNotFoundException {
String fileName = "c:\\temp\\sample-10KB.txt" ;
File file = new File (fileName) ;//use UTF-8 encoding
try (Scanner scanner = new Scanner(file, "UTF-8" ) ) {
String line;
boolean hasNextLine = false ;
while (hasNextLine = scanner.hasNextLine ( ) ) {
line = scanner.nextLine ( ) ;
Organisation.out.println (line) ;
}
}
}
}
New I/O – Reading Bytes
Files.readAllBytes()
Fifty-fifty though the documentation for this method states that "information technology is not intended for reading in big files" I establish this to exist the absolute best performing file reading method, even on files as large every bit 1GB.
1
2
3
four
v
6
seven
8
9
x
xi
12
13
14
xv
16
17
import coffee.io.File ;
import java.io.IOException ;
import coffee.nio.file.Files ;public course ReadFile_Files_ReadAllBytes {
public static void main( String [ ] pArgs) throws IOException {
Cord fileName = "c:\\temp\\sample-10KB.txt" ;
File file = new File (fileName) ;byte [ ] fileBytes = Files.readAllBytes (file.toPath ( ) ) ;
char singleChar;
for ( byte b : fileBytes) {
singleChar = ( char ) b;
System.out.impress (singleChar) ;
}
}
}
tertiary Party I/O – Reading Text
Commons – FileUtils.readLines()
Apache Commons IO is an open source Java library that comes with utility classes for reading and writing text and binary files. I listed it in this article because information technology tin be used instead of the built in Java libraries. The class nosotros're using is FileUtils.
For this article, version two.six was used which is compatible with JDK 1.seven+
Annotation that yous need to explicitly specify the encoding and that method for using the default encoding has been deprecated.
1
two
iii
iv
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import java.io.File ;
import java.io.IOException ;
import java.util.List ;import org.apache.eatables.io.FileUtils ;
public class ReadFile_Commons_FileUtils_ReadLines {
public static void master( String [ ] pArgs) throws IOException {
Cord fileName = "c:\\temp\\sample-10KB.txt" ;
File file = new File (fileName) ;List fileLinesList = FileUtils.readLines (file, "UTF-8" ) ;
for ( String line : fileLinesList) {
System.out.println (line) ;
}
}
}
Guava – Files.readLines()
Google Guava is an open source library that comes with utility classes for common tasks like collections handling, cache management, IO operations, string processing.
I listed it in this commodity because it can be used instead of the built in Java libraries and I wanted to compare its performance with the Java built in libraries.
For this article, version 23.0 was used.
I'm not going to examine all the different ways to read files with Guava, since this article is not meant for that. For a more than detailed wait at all the unlike ways to read and write files with Guava, have a look at Baeldung'south in depth article.
When reading a file, Guava requires that the graphic symbol encoding be set explicitly, but like Apache Commons.
Compatibility note: This code was tested successfully on Java 8 and 9. I couldn't get information technology to work on Java 7 and kept getting "Unsupported major.pocket-size version 52.0" error. Guava has a separate API doc for Java 7 which uses a slightly dissimilar version of the Files.readLine() method. I thought I could get it to work but I kept getting that mistake.
1
ii
iii
4
v
6
7
8
9
x
11
12
13
fourteen
15
16
17
18
19
import java.io.File ;
import java.io.IOException ;
import coffee.util.List ;import com.google.common.base of operations.Charsets ;
import com.google.common.io.Files ;public class ReadFile_Guava_Files_ReadLines {
public static void master( String [ ] args) throws IOException {
Cord fileName = "c:\\temp\\sample-10KB.txt" ;
File file = new File (fileName) ;Listing fileLinesList = Files.readLines (file, Charsets.UTF_8 ) ;
for ( Cord line : fileLinesList) {
Organisation.out.println (line) ;
}
}
}
Operation Testing
Since there are and then many ways to read from a file in Java, a natural question is "What file reading method is the best for my situation?" So I decided to test each of these methods against each other using sample data files of different sizes and timing the results.
Each code sample from this article displays the contents of the file to a cord and then to the panel (System.out). Notwithstanding, during the performance tests the System.out line was commented out since it would seriously slow down the performance of each method.
Each performance test measures the time it takes to read in the file – line by line, character by character, or byte past byte without displaying annihilation to the console. I ran each exam 5-ten times and took the average then as not to let whatsoever outliers influence each test. I too ran the default encoding version of each file reading method – i.e. I didn't specify the encoding explicitly.
Dev Setup
The dev surround used for these tests:
- Intel Core i7-3615 QM @2.3 GHz, 8GB RAM
- Windows 8 x64
- Eclipse IDE for Coffee Developers, Oxygen.2 Release (4.7.2)
- Java SE ix (jdk-ix.0.four)
Data Files
GitHub doesn't allow pushing files larger than 100 MB, and then I couldn't observe a applied way to shop my large test files to permit others to replicate my tests. So instead of storing them, I'm providing the tools I used to generate them so you tin create exam files that are similar in size to mine. Obviously they won't be the same, but you lot'll generate files that are similar in size as I used in my performance tests.
Random String Generator was used to generate sample text and then I simply copy-pasted to create larger versions of the file. When the file started getting besides big to manage inside a text editor, I had to use the command line to merge multiple text files into a larger text file:
copy *.txt sample-1GB.txt
I created the following 7 information file sizes to test each file reading method across a range of file sizes:
- 1KB
- 10KB
- 100KB
- 1MB
- 10MB
- 100MB
- 1GB
Performance Summary
There were some surprises and some expected results from the functioning tests.
Every bit expected, the worst performers were the methods that read in a file grapheme by character or byte by byte. Simply what surprised me was that the native Java IO libraries outperformed both tertiary party libraries – Apache Commons IO and Google Guava.
What'due south more – both Google Guava and Apache Eatables IO threw a java.lang.OutOfMemoryError when trying to read in the one GB test file. This likewise happened with the Files.readAllLines(Path) method but the remaining 7 methods were able to read in all test files, including the 1GB exam file.
The post-obit table summarizes the average time (in milliseconds) each file reading method took to consummate. I highlighted the summit iii methods in greenish, the boilerplate performing methods in yellowish and the worst performing methods in red:
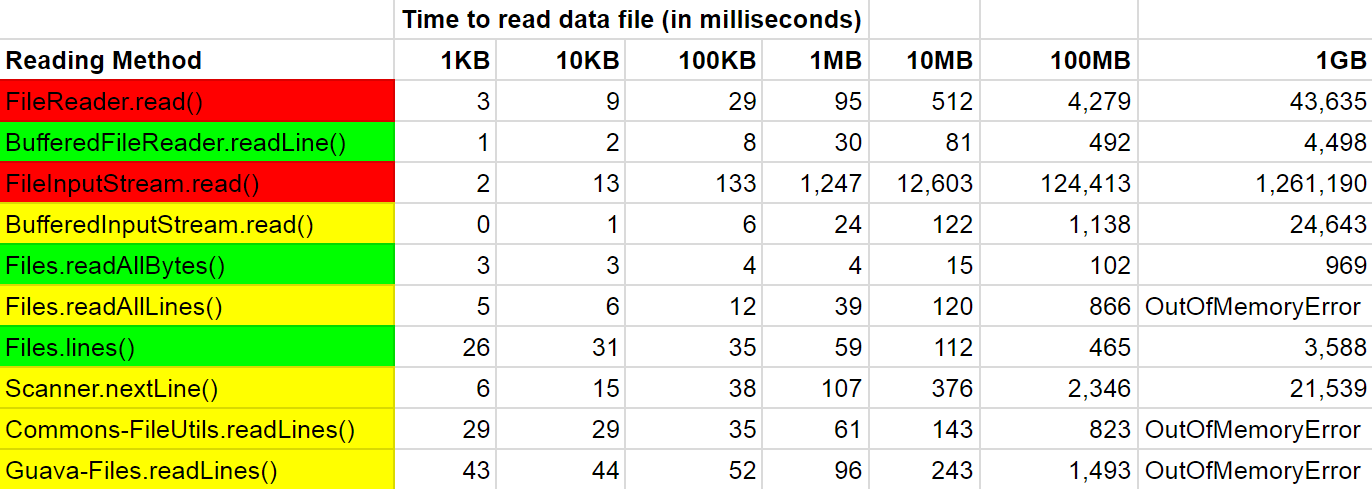
The following nautical chart summarizes the higher up table but with the following changes:
I removed java.io.FileInputStream.read() from the chart because its performance was so bad it would skew the entire nautical chart and you wouldn't see the other lines properly
I summarized the data from 1KB to 1MB because after that, the nautical chart would get too skewed with and then many nether performers and also some methods threw a java.lang.OutOfMemoryError at 1GB
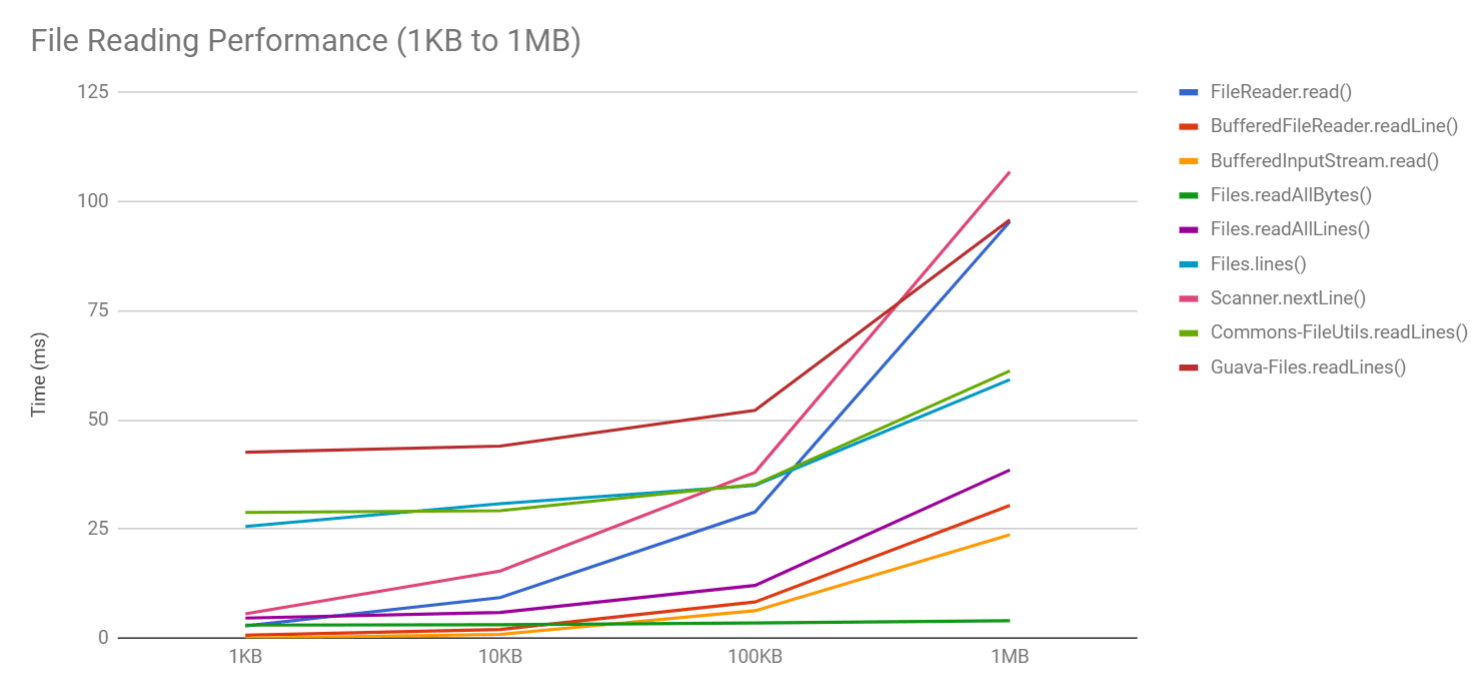
The Winners
The new Java I/O libraries (java.nio) had the best overall winner (java.nio.Files.readAllBytes()) but information technology was followed closely behind by BufferedReader.readLine() which was also a proven top performer across the lath. The other fantabulous performer was java.nio.Files.lines(Path) which had slightly worse numbers for smaller test files simply really excelled with the larger examination files.
The absolute fastest file reader across all data tests was java.nio.Files.readAllBytes(Path). It was consistently the fastest and even reading a 1GB file only took most 1 second.
The following chart compares functioning for a 100KB examination file:
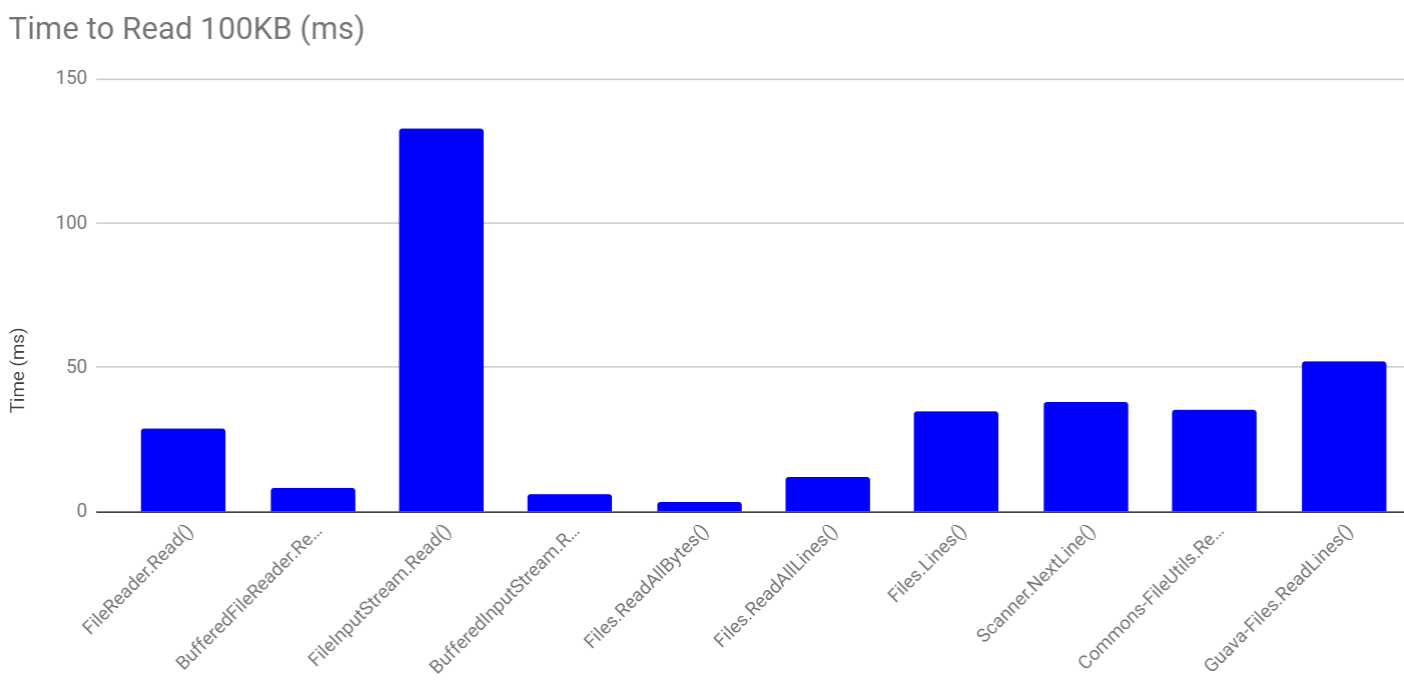
You can see that the lowest times were for Files.readAllBytes(), BufferedInputStream.read() and BufferedReader.readLine().
The following chart compares performance for reading a 10MB file. I didn't bother including the bar for FileInputStream.Read() because the performance was and so bad it would skew the entire chart and you couldn't tell how the other methods performed relative to each other:
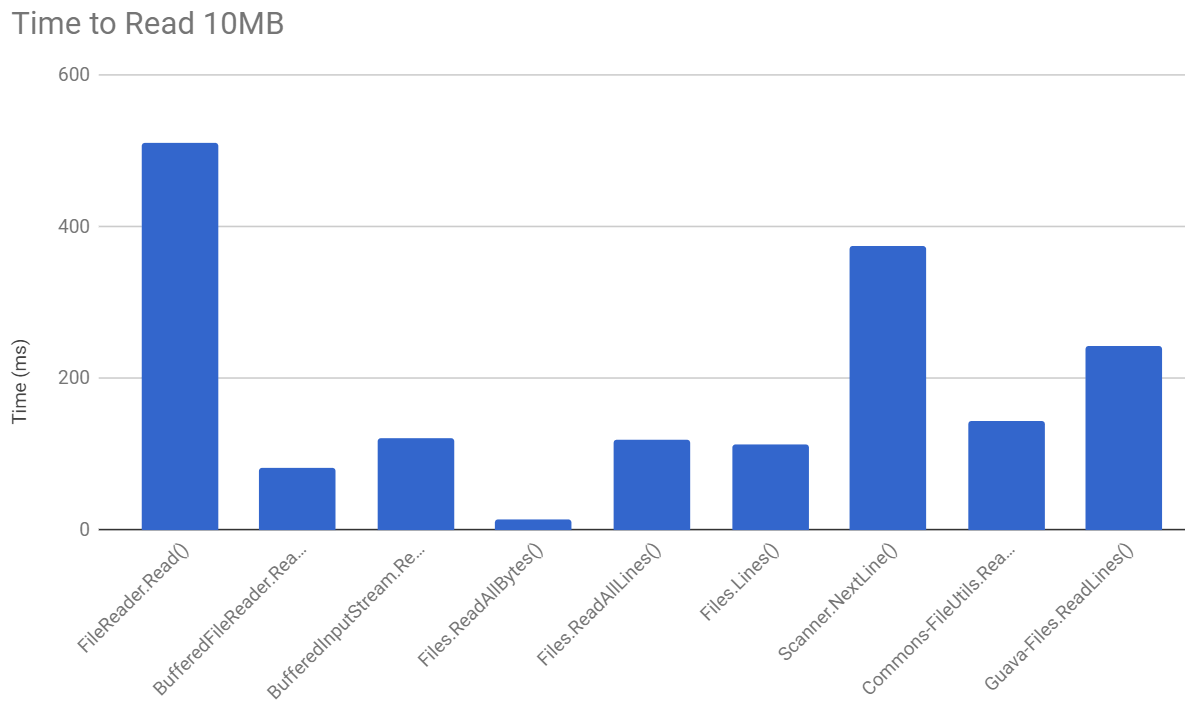
Files.readAllBytes() actually outperforms all other methods and BufferedReader.readLine() is a afar second.
The Losers
Equally expected, the absolute worst performer was java.io.FileInputStream.read() which was orders of magnitude slower than its rivals for most tests. FileReader.read() was besides a poor performer for the same reason – reading files byte past byte (or character past character) instead of with buffers drastically degrades performance.
Both the Apache Eatables IO FileUtils.readLines() and Guava Files.readLines() crashed with an OutOfMemoryError when trying to read the 1GB examination file and they were about average in performance for the remaining test files.
java.nio.Files.readAllLines() also crashed when trying to read the 1GB test file but it performed quite well for smaller file sizes.
Performance Rankings
Hither'south a ranked list of how well each file reading method did, in terms of speed and treatment of large files, every bit well equally compatibility with different Java versions.
| Rank | File Reading Method |
|---|---|
| 1 | java.nio.file.Files.readAllBytes() |
| 2 | coffee.io.BufferedFileReader.readLine() |
| 3 | java.nio.file.Files.lines() |
| iv | coffee.io.BufferedInputStream.read() |
| 5 | java.util.Scanner.nextLine() |
| 6 | java.nio.file.Files.readAllLines() |
| 7 | org.apache.commons.io.FileUtils.readLines() |
| 8 | com.google.common.io.Files.readLines() |
| 9 | java.io.FileReader.read() |
| ten | java.io.FileInputStream.Read() |
Conclusion
I tried to nowadays a comprehensive set of methods for reading files in Java, both text and binary. We looked at fifteen different ways of reading files in Coffee and we ran performance tests to run across which methods are the fastest.
The new Java IO library (coffee.nio) proved to be a great performer merely so was the classic BufferedReader.
Source: https://funnelgarden.com/java_read_file/
0 Response to "Java Read File and Separate Name and Age"
Post a Comment